全链路支撑大模型国产化“Day0适配”,国产算力新拐点要来了?
AI导读:
近期,DeepSeek官宣并开源其新一代旗舰模型V4,全面适配华为昇腾国产芯片。从底层算子到通信协议,从显存调度到框架适配,持续推进大模型与国产算力的原生协同,逐步摆脱对NVIDIA依赖,这也标志着国产大模型与国产算力进入了
近期,DeepSeek官宣并开源其新一代旗舰模型V4,全面适配华为昇腾国产芯片。从底层算子到通信协议,从显存调度到框架适配,持续推进大模型与国产算力的原生协同,逐步摆脱对NVIDIA依赖,这也标志着国产大模型与国产算力进入了“Day0适配”的新阶段。
这不仅是技术路径的调整,更是AI基础设施范式的深层跃迁。过去,大模型开发往往基于英伟达GPU完成训练,再向国产芯片做“后补式”迁移——成本高、周期长、性能损耗显著。而“Day 0适配”的核心在于:模型从预训练阶段起便与底层算力深度绑定,通过“算力—模型协同优化”,实现开箱即用的高性能。
这要求国产算力集群具备从0到1支撑大模型训练、推理与持续演进的完整能力——而商汤大装置,已在基础设施层面完成了这一技术路径的全链条验证,为国产算力规模化落地提供可复制经验。
全链路支撑世界模型与多模态模型的“Day0适配”
新民晚报记者了解到,商汤大装置为多模态、世界模型与国产算力的“Day 0适配”提供全栈技术支撑。
a在世界模型方向,开悟世界模型3.0已具备在国产算力集群上完成蒸馏、训练与推理的全流程能力,并完成与沐曦C系列GPU的“Day 0适配”。在这个过程中,开悟3.0采用芯片与模型协同编译方案,结合算子级耗时针对性优化,使模型运行性能直接提升300%,复杂任务处理效率实现大幅跃升。
在多模态模型方向,Seko系列模型已完成与寒武纪芯片的深度适配,实现从语言到多模态的全面支持;同时依托LightX2V框架的插件化适配能力,可快速对接多种国产硬件,具备良好的生态延展性。
商汤大装置为其提供了底层算力管理、任务调度和性能优化的完整技术支撑,使“Day0适配”从概念走向可落地的实践方案,实现模型训练、推理与迭代的全流程高效协同。
从异构协同到推理性能倍增
国产模型与国产算力的深度绑定,核心不在单点突破,而在体系化能力的构建。针对国产化芯片兼容难、异构芯片协同效率低、推理侧性能挑战大等现实痛点,商汤大装置通过全链路协同优化,形成了覆盖训练到推理的完整能力栈。
在兼容层,针对国产化兼容难题,LightX2V框架设计了强兼容的国产化适配插件模式,可快速完成各类国产硬件的适配接入,目前已支持寒武纪、沐曦、海光DCU、昇腾910B等多款主流芯片。实践层面,为了更好地释放国产算力优势,Seko系列模型与LightX2V框架在设计之初即引入了低比特量化、压缩通信、稀疏注意力等硬件友好创新机制,将国产芯片的推理性能提升3倍以上。
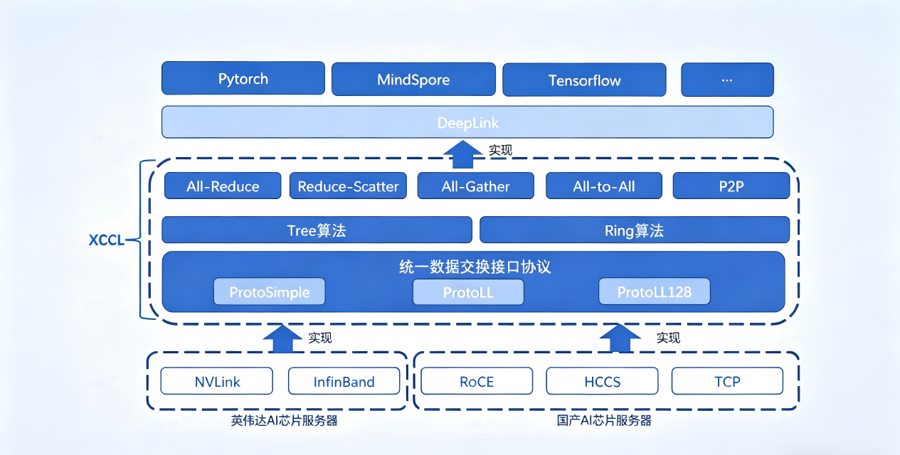
训练侧,针对异构芯片难以协同、大规模训练效率低的难题,商汤大装置构建了基于XCCL与DeepLink的统一异构适配体系。通过分层通信、自动并行调度与动态负载均衡策略等,实现万卡规模集群高效协同,训练效率达到同构集群的95%以上,算力利用率提升至80%,让国产算力真正具备大规模训练能力。
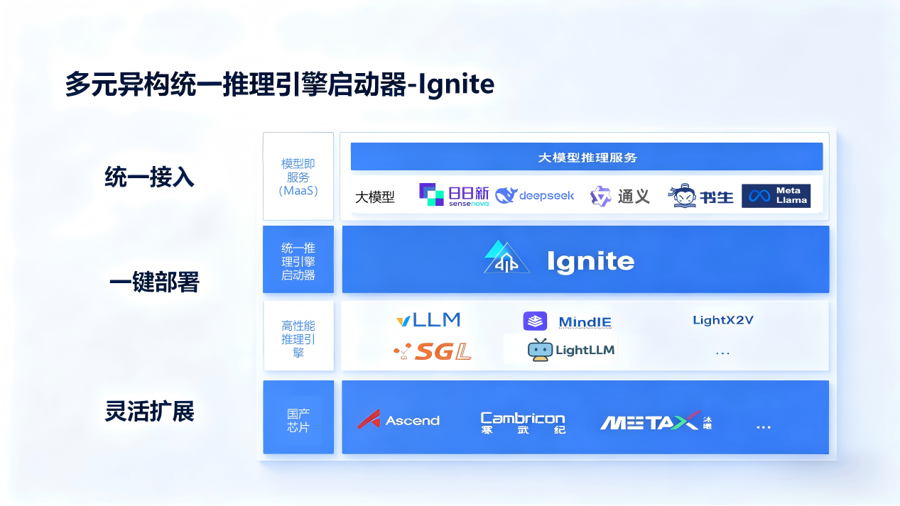
在推理侧,商汤大装置通过Ignite推理引擎启动器,兼容多模型与多引擎体系,通过提供统一API,并在KV Cache管理、多Token预测、算子优化、通信调优上形成全链路能力,实现“一键部署+自适配优化”,显著降低推理门槛。
国产算力新拐点到来
从当前产业进展来看,两个趋势已经愈发清晰——
一是,国产算力生态正从“可用”走向“可规模商用”。随着大模型训练与推理全流程跑通,产业拐点正在加速到来。
二是,多芯片并存将成为长期常态。在这一背景下,决定竞争力的,不再是单一芯片性能,而是跨芯片适配、异构协同与全栈调度能力等,能够高效管理、调度和优化异构芯片运行环境的基础设施,将成为大模型产业落地的核心支撑。
(文章来源:上观新闻)
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。