新京报AI研究院发布第二期大语言模型传媒方向能力测评报告
AI导读:
新京报AI研究院发布第二期中国AI大模型测评报告,对国内11款主流大语言模型在信息搜集能力、新闻写作能力、事实核查与价值观判断能力、翻译能力以及长文本能力五大维度进行测评。结果显示,信息搜集能力和翻译能力表现突出,长文本能力等仍需提升。
1月13日,新京报AI研究院再度发布重磅报告——《大语言模型产品传媒方向能力测评调研报告》(简称《报告》),这是继2024年7月首份大模型赋能传媒能力报告后,新京报贝壳财经对国内11款主流大语言模型的第二次全面测评。本次测评涵盖信息搜集能力、新闻写作能力、事实核查与价值观判断能力、翻译能力以及长文本能力五大维度。
《报告》基于新闻媒体行业人士对11款大语言模型的满意度打分,涉及16道测试题和176个生成结果。结果显示,信息搜集能力和翻译能力表现突出,达到及格线,而长文本能力、事实核查与价值观判断能力、新闻写作能力则排名靠后。与半年前相比,信息搜集能力跃升至首位,长文本能力也有显著提升。
值得注意的是,测评中发现多款大模型存在“幻觉”问题,即因审题不严或内容审核不灵活导致生成脱离实际的答案。例如,夸克AI在回答爆款文章建议时,提及了不存在的中国航天局月球探测任务。此外,虽然长文本能力有所提升,但大模型仍无法胜任财报分析等严谨内容。
本次测评的大模型包括文心一言、通义千问、腾讯元宝、讯飞星火、豆包、百小应、智谱、Kim i、天工AI、夸克AI、海螺AI。测试通过C端交互窗口进行,取第一次回答为标准结果。
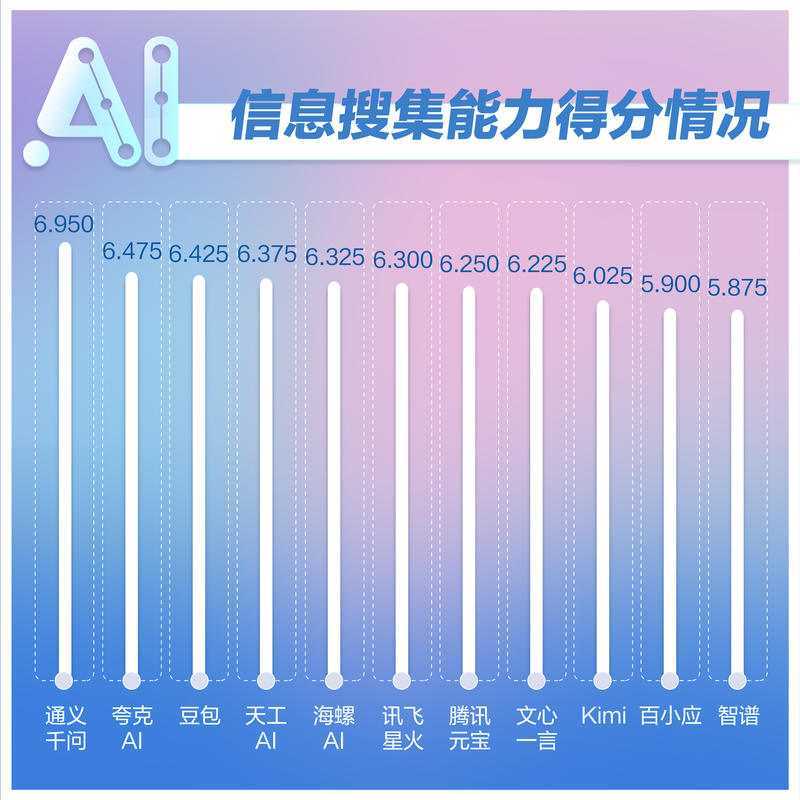
在信息搜集能力方面,通义千问以6.95分位居榜首,夸克AI紧随其后。讯飞星火初期无法回答某题,但后期已能完整生成。多款大模型因理解偏差或忽视时间限制导致分数被拉低。在实际应用中,需谨慎选择和使用模型,对有时间限制的问题可进行多次生成。
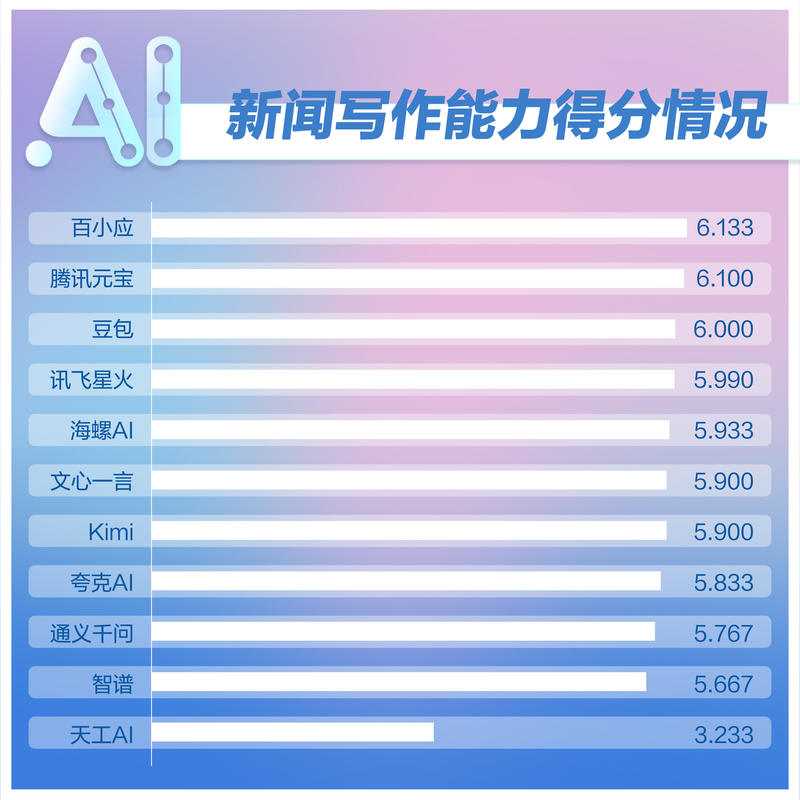
新闻写作能力测试中,百小应蝉联第一,腾讯元宝和豆包分列二三。各模型得分差距较小,输出同质化严重。天工AI因回答背离现实得分垫底。使用大模型生成内容需通过反复生成和追问修正,才能得到最佳结果。
事实核查与价值观判断能力测试中,腾讯元宝夺冠,文心一言和Kim i并列第二。大模型大多能正确识别谣言并进行理性分析,但对相对敏感话题的评论无偏倚。本次测评该维度得分排名倒数第二,跌破及格线,说明依赖大模型无法辨别所有谣言,但理性分析可行。
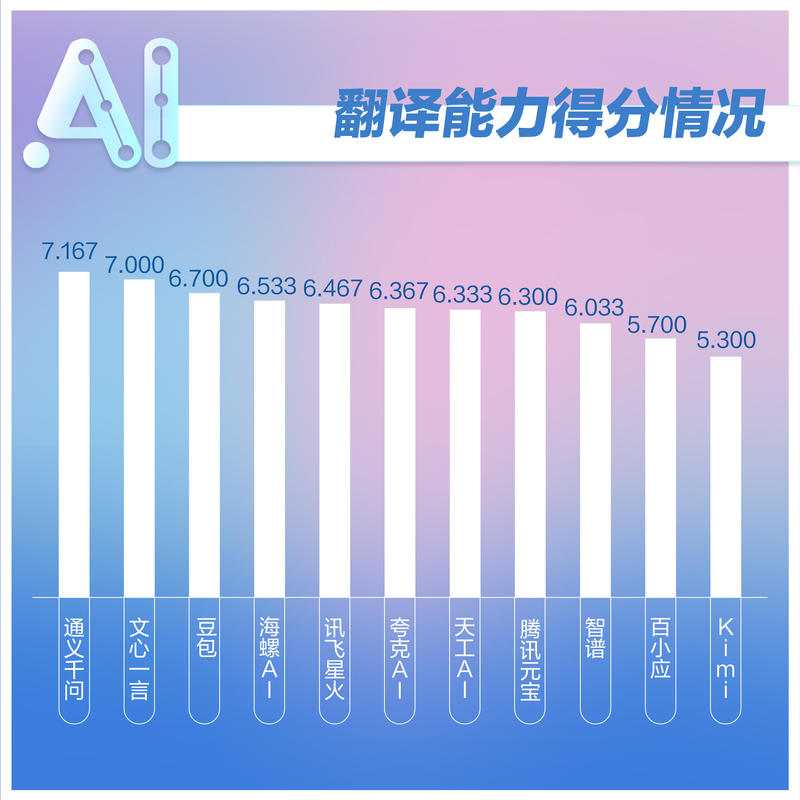
翻译能力测试中,通义千问、文心一言、豆包排名前三。不少大模型因生成失败或触及内部审核机制导致分数受影响。对于特殊文章的翻译,AI与人工仍有差距。普通文章翻译和英文采访提纲撰写方面,各模型表现及格,但格式和生成内容长度有所区别。
长文本能力测试中,海螺AI稳居第一,豆包和腾讯元宝分列二三。绝大多数大模型能够通过文内检索找到答案,技术得到增强。但在财报对比方面,大模型仍能力不足。对于内容严谨程度要求较高的财报分析等工作,大模型需审慎对待。
本期测评揭示了大模型产品在长文本能力方面的进步,特别是文内检索能力得到大幅提升。然而,对于财报分析等严谨工作,大模型仍显力不从心。传媒从业者需审慎使用大模型,以确保信息的准确性和可靠性。(文章来源:新京报)


郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。









