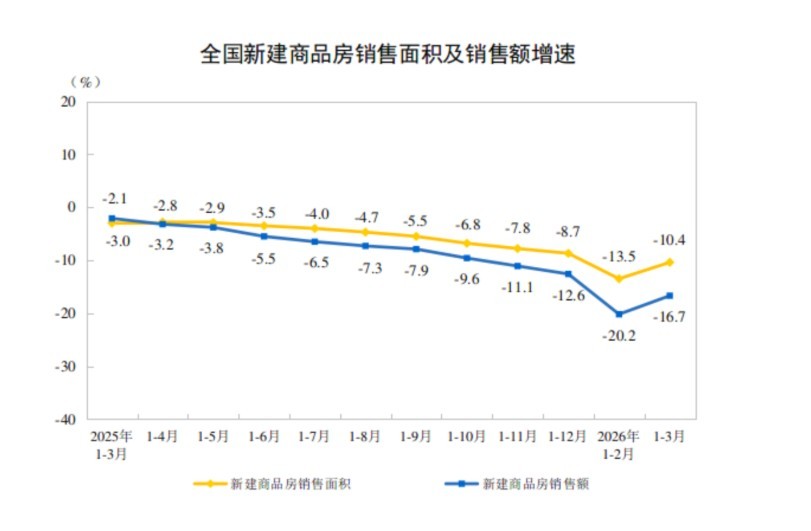
谷歌RT-2机器人模型实现重大突破
AI导读:
谷歌最新推出的RT-2机器人模型,作为新型视觉-语言-动作模型,实现了从“灭绝动物”到“塑料恐龙”的逻辑推理,具备符号理解、推理和人类识别三大能力,泛化能力大幅提高,是机器人领域的一大突破。
之前,机器人难以操控未见过的物品,也难以实现从“灭绝动物”到“塑料恐龙”的逻辑推理。然而,谷歌最新推出的RT-2机器人模型打破了这一局限。
RT-2是一款新型视觉-语言-动作(VLA)模型,能够从网络和机器人数据中学习,并将这些知识转化为控制机器人的通用指令。这一创新使得RT-2不仅能直接接收并理解人类指令,还能进行逻辑推理,并转化为机器人可执行的分阶段指令。
RT-2具备三大核心能力:符号理解、推理和人类识别。例如,在接收到“捡起灭绝的动物”指令后,RT-2能够准确识别出塑料恐龙并执行抓取动作。这一能力在机器人领域堪称重大突破。
在符号理解方面,RT-2可以从视觉语言预训练中获取语义知识,这些知识在机器人数据中并不存在。例如,它能理解并执行“将苹果移到3号位置”等指令。在推理方面,RT-2将VLM的各种推理能力用于任务控制,包括视觉推理、数学推理和多语言理解。在人类识别方面,RT-2能够完成以人类为中心的任务,如“将可乐罐移到戴眼镜的人身边”。
此外,研究人员还将机器人控制与思维链推理相结合,使得RT-2能够更好地适用于不同的、机器此前未见过的场景。相较于其他模型,RT-2的泛化能力大幅提高,较前者提高了3倍有余。
加利福尼亚大学伯克利分校的机器人学教授Ken Goldberg对RT-2给予了高度评价,认为谷歌利用人工智能语言模型赋予机器人推理和随机应变的新技能,是一个很有希望的突破。

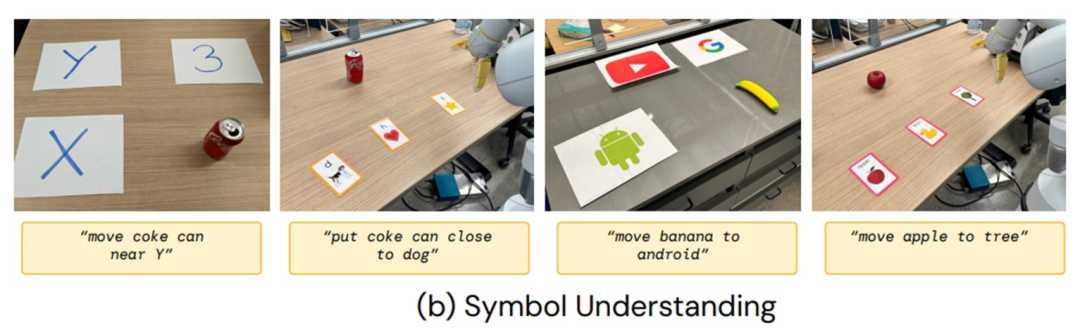 图|符号理解指令示例
图|符号理解指令示例
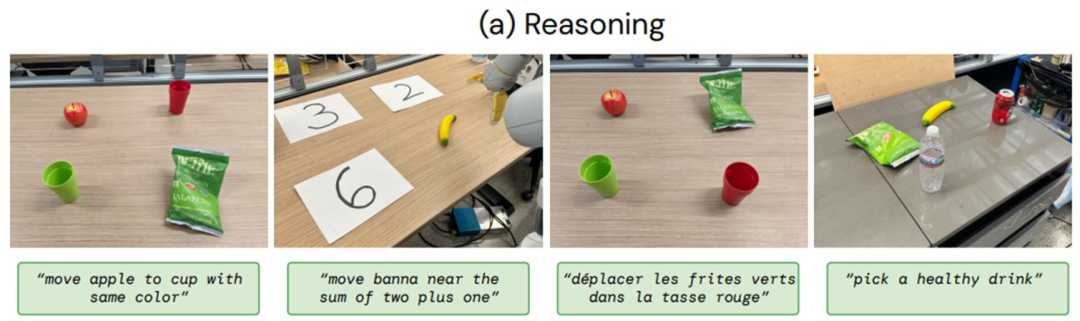 图|推理指令示例
图|推理指令示例
 图|人类识别指令示例
图|人类识别指令示例
 图|思维链推理示例
图|思维链推理示例
(文章来源:财联社)
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。