DeepSeek-V4千呼万唤始出来,华为超节点支持部署
AI导读:
4月24日,市场期待已久的DeepSeek-V4模型预览版正式发布。新模型支持百万token(词元)超长上下文,DeepSeek称其在智能体能力、世界知识和推理性能上均实现国内与开源领域的领先。
按参数规模不同,DeepSeek-V4系列分
4月24日,市场期待已久的DeepSeek-V4模型预览版正式发布。新模型支持百万token(词元)超长上下文,DeepSeek称其在智能体能力、世界知识和推理性能上均实现国内与开源领域的领先。
按参数规模不同,DeepSeek-V4系列分为DeepSeek-V4-Pro和DeepSeek-V4-Flash两个版本。前者的总参数量达1.6万亿、激活参数为490亿;后者的总参数量为2840亿,激活参数为130亿。
尽管轻量版DeepSeek-V4-Flash的参数量更小,但推理能力接近DeepSeek-V4-Pro,在运行智能体简单任务上与DeepSeek-V4-Pro旗鼓相当,但在高难度任务中仍有差距。官方称DeepSeek-V4-Flash主打性价比,能够提供更加快捷和经济的API服务。
技术报告指出,DeepSeek-V4系列在长上下文场景中具有极高的效率。和上一代DeepSeek-V3.2模型相比,DeepSeek-V4-Pro大幅降低了对计算和显存的需求。在100万上下文设置下,DeepSeek-V4-Pro的单token推理计算量仅为DeepSeek-V3.2的27%,KV缓存(一种加速模型推理生成的机制)仅为其10%。DeepSeek称这得益于一种全新的注意力机制设计。
“这使我们能够在实际应用中稳定支持百万级上下文,从而使长时序任务更加可行。”技术报告写道。
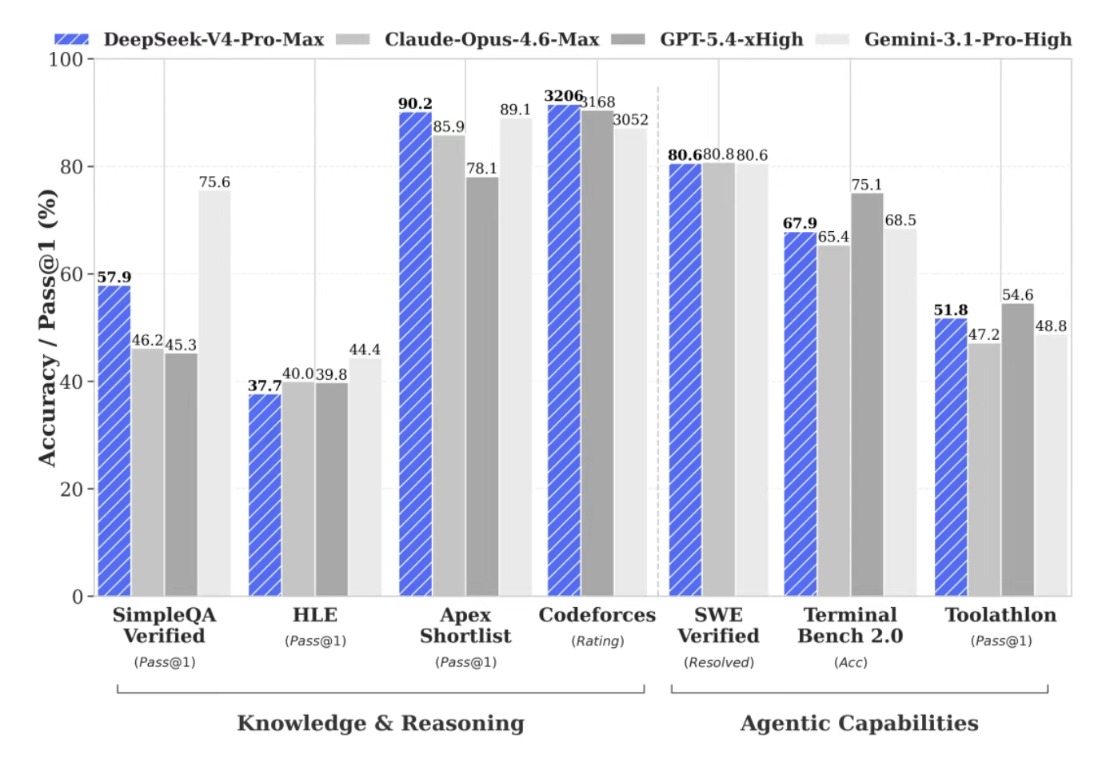
DeepSeek-V4-Pro-Max的测试性能。
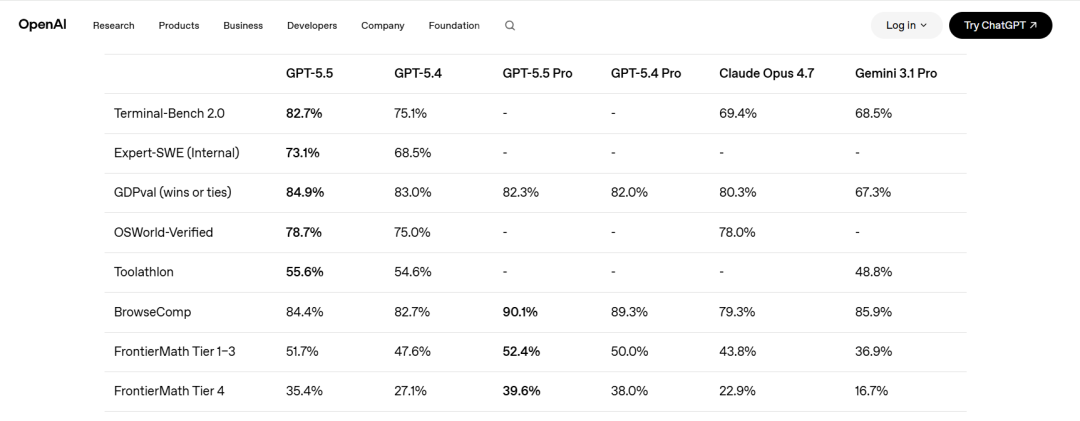
具体性能表现上,技术报告显示,DeepSeek-V4-Pro-Max(即DeepSeek-V4-Pro的最大推理强度模式)的智能体能力与月之暗面Kimi-K2.6和智谱GLM-5.1等领先的开源模型表现相当,但略逊于顶级闭源模型。在内部评估中,DeepSeek-V4-Pro-Max超越Anthropic的Claude Sonnet 4.5,并接近其2025年11月推出的Opus 4.5的水平。
知识能力方面,DeepSeek-V4-Pro-Max在多个测试基准上显著优于领先的开源模型,仍落后于谷歌旗下的顶尖闭源模型Gemini-3.1-Pro,不过差距已显著缩小。
推理性能上,DeepSeek-V4-Pro-Max展现出优于GPT-5.2和Gemini-3.0-Pro的表现,但仍略低于GPT-5.4和Gemini-3.1-Pro。技术报告称这表明其发展水平大约落后当前最先进前沿模型约3至6个月。
DeepSeek未在技术报告中指出新模型预训练所使用的具体芯片型号和规模。而在DeepSeek-V3的技术报告中,曾披露该模型训练仅使用了2048块英伟达H800 GPU。
不过,华为方面在DeepSeek-V4模型发布后表示,华为昇腾芯片一直同步支持DeepSeek系列模型,本次通过双方芯模技术紧密协同,实现昇腾超节点全系列产品支持DeepSeek-V4系列模型。华为称,昇腾950超节点能实现高吞吐、低时延的DeepSeek-V4模型推理部署。
DeepSeek-V4模型的发布,正值DeepSeek公司被曝首次对外融资之际。据科技媒体The Information报道,腾讯和阿里巴巴正在洽谈投资DeepSeek,估值超过200亿美元。腾讯和阿里对此未公开回应。
(文章来源:南方都市报)
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。