红杉中国推出全新AI基准测试工具xbench
AI导读:
红杉中国推出全新AI基准测试工具xbench,采用双轨评估体系和长青评估机制,旨在解决基准测试难以真实反映AI客观能力的问题。该工具将重点关注多模态模型生成商用水平视频、MCP工具可信度、GUI Agents使用动态更新/未训练应用等方向。
类似手机时代厂商发布新机需要“跑个分”,如今AI大模型厂商发布新产品后,同样会通过基准测试(Benchmark)跑分对比。然而,随着基础模型的迅猛发展和AI Agent(智能体)步入规模化应用阶段,基准测试面临严峻挑战:真实反映AI的客观能力愈发困难。
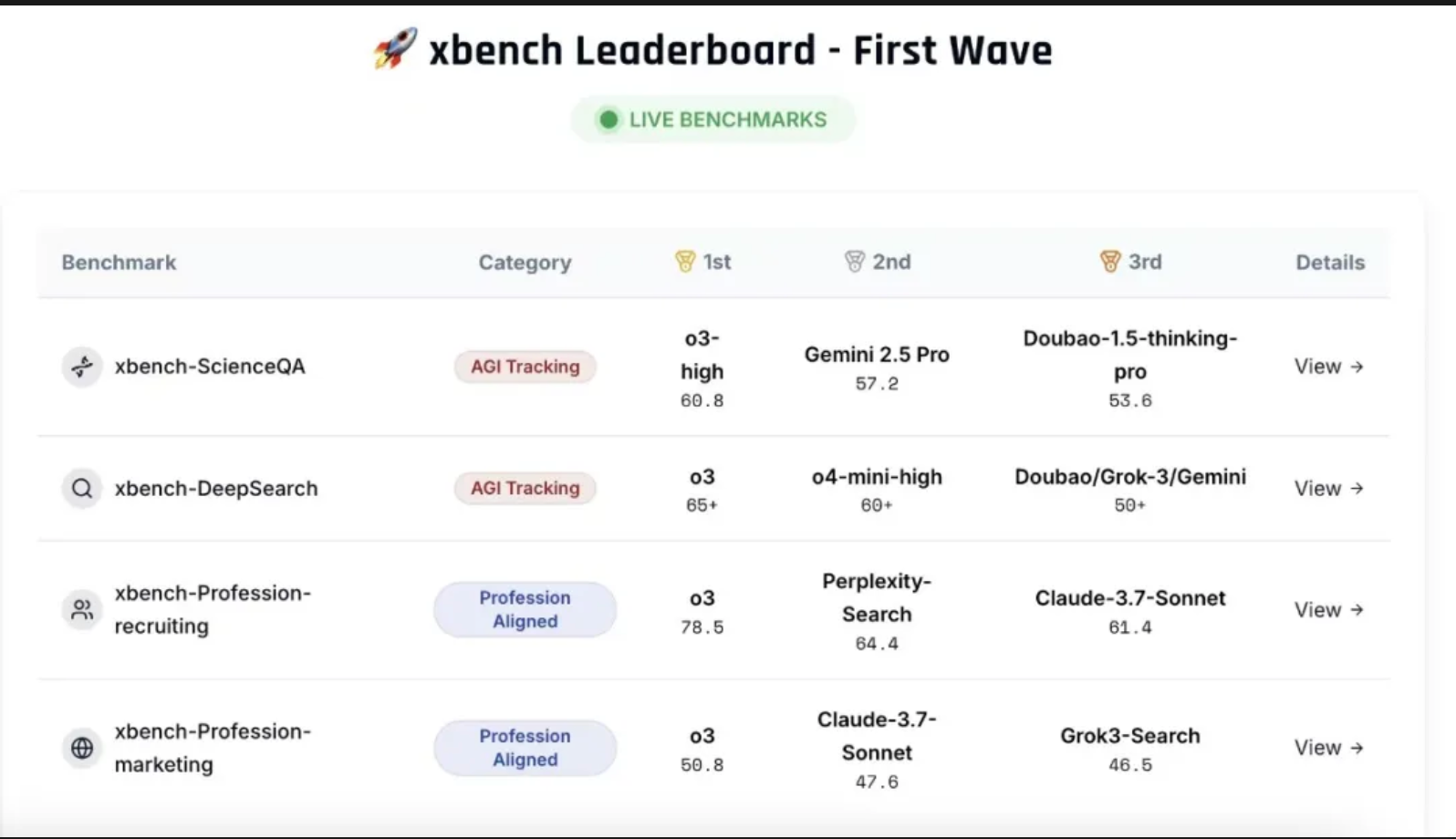
5月26日,红杉中国推出全新AI基准测试工具xbench,该工具由红杉中国携手国内外十余所高校及研究机构,集结数十位博士研究生之力,采用双轨评估体系和长青评估机制,旨在解决行业痛点。
双轨评估体系,即构建多维度测评数据集,同步衡量模型理论能力上限与Agent实际落地价值。长青评估机制,即动态、持续更新的评估方式,有效避免“刷榜”现象,确保评估结果的公正性和准确性。
xbench起源于红杉中国在2022年ChatGPT推出后,对AGI进程和主流模型的内部月评与汇报工具。随着主流模型“刷爆”题目速度加快,基准测试的有效期急剧缩短,xbench应运而生。
此外,相关机构还提出垂直领域Agent评测方法论,构建招聘与营销领域的垂类Agent评测框架。AI Agent的深度搜索能力,是通向AGI的核心能力之一,但评估面临诸多挑战。
AI在长文本处理、多模态、工具使用和推理方面的能力突破,推动了AI Agent的爆炸式增长。有价值的AI Agent评估需与实际任务紧密相关,已成为行业共识。然而,评估结果与AI在现实世界中创造的经济价值仍存在差距。因此,构建特定领域的Agent评估集至关重要。
Agent应用产品版本迭代迅速,外部环境动态变化,测试工具设计需追踪Agent能力的持续增长。红杉推出的xbench-DeepSearch评测集,今年将重点关注多模态模型生成商用水平视频、MCP工具可信度、GUI Agents使用动态更新/未训练应用等方向。
(文章来源:第一财经)
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。






