DeepSeek新论文:软硬件协同推动AI大规模训练和推理
AI导读:
DeepSeek团队发布新论文,深入解读DeepSeek在硬件架构和模型设计方面的关键创新,为实现具有成本效益的大规模训练和推理提供新思路。论文探讨了硬件驱动的模型设计、硬件和模型之间的相互依赖关系以及硬件开发的未来方向,提出了多项创新方法。
近日,Deepseek团队发布了新论文,以DeepSeek-V3为代表,深入解读DeepSeek在硬件架构和模型设计方面的关键创新,为实现具有成本效益的大规模训练和推理提供新思路。其中,DeepSeek创始人兼CEO梁文锋是署名作者之一。
DeepSeek在论文中提到,期望跨越硬件架构和模型设计,采用双重视角探索其间错综复杂的相互作用,以实现具有成本效益的大规模训练和推理。这一研究对于AI领域的发展具有重要意义。
论文主要探讨了三大方向:硬件驱动的模型设计、硬件和模型之间的相互依赖关系,以及硬件开发的未来方向。特别是在内存效率、成本控制、推理速度等方面,DeepSeek提出了多项创新方法。

揭秘DeepSeek模型设计原则
DeepSeek模型设计原则聚焦于内存效率、成本控制、推理速度等关键方面。面对大量内存资源需求,DeepSeek通过多头潜在注意力(MLA)和FP8混合精度训练技术等手段,显著降低了内存消耗。
在成本控制方面,DeepSeek开发了DeepSeekMoE混合专家架构,通过选择性激活专家参数来降低计算成本,实现了与密集模型相当甚至更优的性能。同时,该架构也利于个人使用和本地部署。
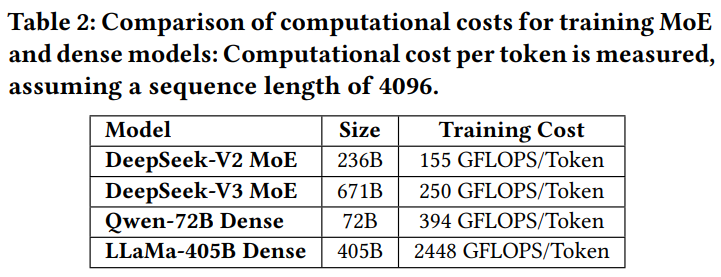
在提高推理速度方面,DeepSeek引入了高带宽纵向扩展网络、重叠计算和通信、多token预测框架等方法,有效提升了推理速度。
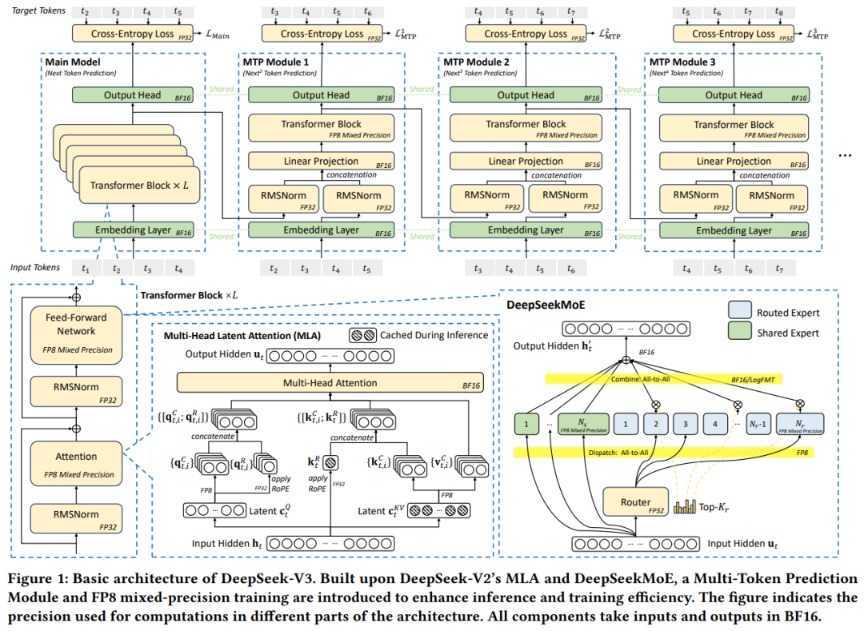
软硬件协同突破效率极限
基于设计原则,DeepSeek在低精度训练、互连优化、网络拓扑等方面提出了具体细节。特别是在低精度技术突破方面,DeepSeek通过采用FP8混合精度训练,将模型内存占用直接减少50%。
未来,下一代AI基础设施将如何升级?DeepSeek从硬件架构的角度提出六大方向,直面未来挑战并提出解决方案,涉及内存、互连、网络、计算等核心领域,为AI领域的未来发展提供了有益参考。
(文章来源:上海证券报)
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。






