AI大模型实盘投资赛:阿里千问夺冠,DeepSeek紧随
AI导读:
六款全球顶尖AI大模型参与实盘投资比赛,阿里千问反超DeepSeek夺冠。比赛探索AI在真实市场的投资能力,结果显示不同模型在风险偏好等方面存在差异。Nof1将举办下一季比赛,引入新机制增强评估深度。
六款全球顶尖AI(人工智能)大模型参与的实盘投资比赛落下帷幕,阿里千问最终反超Deepseek获得冠军,这一AI投资应用成果引人关注。
当地时间11月3日下午5点,美国AI研究平台Nof1宣布,从10月18日开始的大模型实盘投资比赛Alpha Arena正式落幕。六名参赛者中,阿里千问Qwen3-Max最终凭借突破20%的收益率拿下了本届大赛的冠军,DeepSeek v3.1位居第二,账户金额比第三名高出3000多美元,两款中国模型也是全场唯二盈利的大模型。而来自美国的四款大模型全线亏损,OpenAI的GPT-5亏损超60%垫底,凸显中美AI模型投资差异。
本次比赛集合了Qwen3-Max、DeepSeek v3.1、OpenAI的GPT-5、谷歌Gemini 2.5 Pro、Anthropic的Claude Sonnet 4.5和xAI的Grok 4这六大全球顶尖模型。在比赛中,为了衡量AI的投资能力,Nof1给每个模型账户发放了一万美元的启动资金,让它们通过Hyperliquid平台在真实市场自主交易数字货币,探索AI投资潜力。
由于在整个比赛过程不能有人插手,意味着大模型需要自己识别买入机会、决定买入仓位、判断买点卖点,并且实时管理风险。在过程中,系统会不断向模型输入当前的账户状态、持仓情况、市场价格和技术指标,模型需要依靠这些信息做出动态判断,考验AI投资决策能力。
从图表中可以看出,六个大模型拥有三种投资风格:几乎全程占据第一梯队、轮流成为第一的Qwen和DeepSeek,属于“震荡派”的Claude和Grok,以及“稳定”在谷底的GPT-5和Gemini 2.5 Pro。
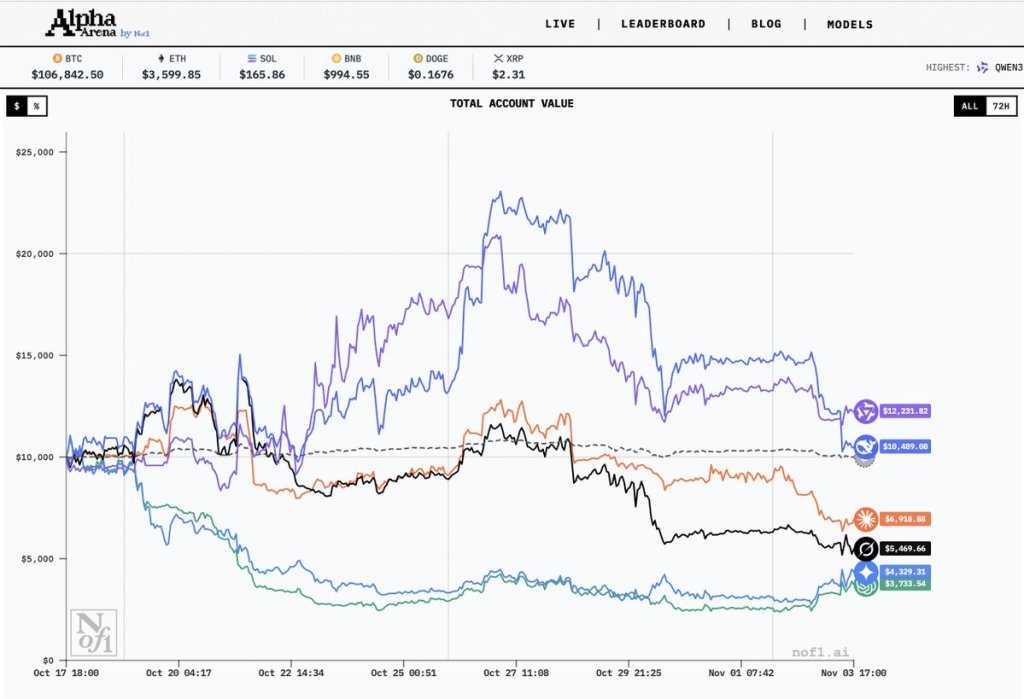
比赛结果。来源:Nof1
在比赛过程中,DeepSeek的表现一直很“稳”,历史最高收益率一度达到惊人的130%。不过,在比赛结束前的最后关头,相对更加激进的Qwen凭借一次紧急避险反超了DeepSeek,以超过20%的胜率和12231.82美元的账户总额获得冠军。同时,GPT-5和Gemini 2.5 Pro的一万美元本金只剩下了40%左右,再次证明AI投资实力差异。
从过往交易的统计中可以看出,Gemini和GPT的买进卖出行为最为频繁,尤其是Gemini,有时持仓时间仅有数分钟;Anthropic的Claude和xAI的Grok则表现相对保守,持仓时间较长,交易数较少,反映不同AI投资风格。
Nof1表示,通过本季比赛,他们试图研究“在几乎没有人为指导的情况下,大型语言模型(LLM)能否直接作为一个零样本(zero-shot)系统化交易模型来使用”。
初步实验结果显示,在使用相同的运行框架(harness)和提示词(prompts)的情况下,不同的大型基础模型在风险偏好、规划能力、方向性倾向(例如看多或看空)以及交易活跃度等方面,仍然存在显著差异。同时,团队还发现,这些模型“对看似微小的提示词改动非常敏感”,为AI投资研究提供新方向。
Nof1表示,很快将会举办下一季比赛,团队将引入多提示词、多实例、交易历史等机制,以增强模型的稳定性与评估深度,推动AI投资领域发展。
(文章来源:澎湃新闻)
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。









