DeepSeek发布新OCR模型,探索文本压缩新方向
AI导读:
DeepSeek发布新OCR模型,利用视觉模态实现文本高效压缩,解码精度高达97%,并提出用光学压缩模拟人类遗忘机制,为处理超长上下文提供新方向。
Deepseek又发布新OCR模型了,这一模型在文本压缩领域展现出了强大潜力(OCR模型)。10月20日,DeepSeek在Github开源了这一新模型,并发布《DeepSeek-OCR:Contexts Optical Compression》(《DeepSeek OCR:上下文光学压缩》)论文,详细解释了这一成果。当前的大语言模型在处理过程中面临着重大的计算挑战,尤其是文本内容过长的问题,因此团队探索了一种具有潜力的解决方案:利用视觉模态作为文本信息的高效压缩介质(文本压缩)。
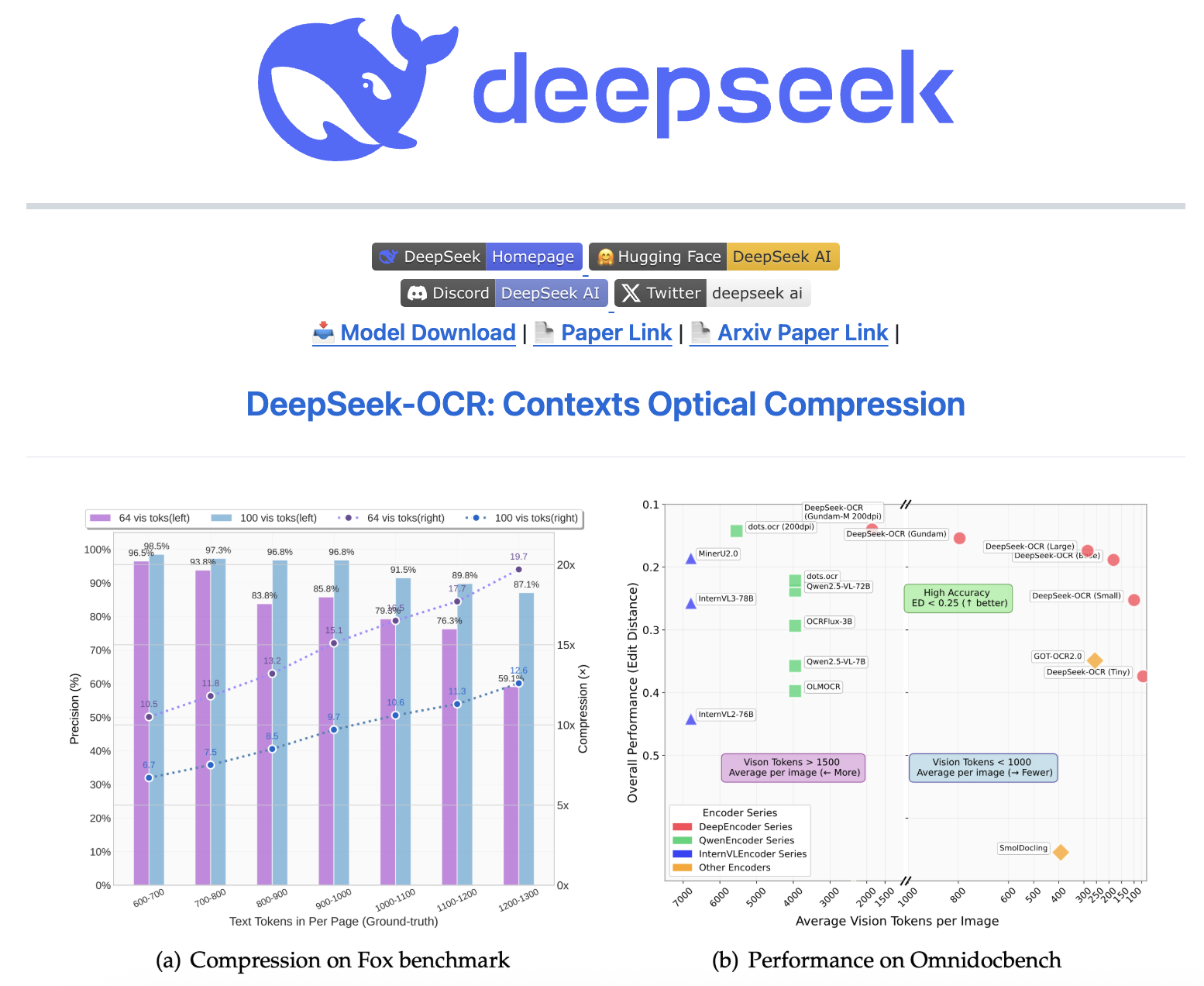
具体来说,这一OCR模型可以将文本压缩成视觉模态,实现“一图胜千言”的效果,这样可以消耗更少的Token。测试显示,通过文本到图像的方法可以实现近10倍无损上下文压缩,OCR准确率还能保持在97%以上(视觉模态)。在实际应用中,单张A100-40G显卡,可支持每日20万页以上的大语言模型/视觉语言模型训练数据生成。
DeepSeek-OCR由两个核心组件组成,其中DeepEncoder(编码器)负责图像特征提取和压缩,DeepSeek3B-MoE(解码器)负责从压缩后的视觉Token中重建文本。解码器采用DeepSeek-3B-MoE架构,虽然只有3B参数,但采用了MoE(混合专家)设计,64个专家中激活6个,再加2个共享专家,实际激活参数约5.7亿。这也让模型既有30亿参数模型的表达能力,又保持了5亿参数模型的推理效率(模型效率)。
实验数据显示,当文本token数量在视觉token的10倍以内时,模型的解码(OCR)精度可达97%;即使在压缩率达到20倍的情况下,OCR准确率仍保持在约60%。DeepSeek团队在论文里还提出了具有想象力的未来——用光学压缩模拟人类的遗忘机制。人类的记忆会随时间衰退,越久远的事情记得越模糊,那是否AI也能这样?于是,团队设计将更久远的上下文,逐步缩小渲染图像的大小,以进一步减少token消耗(AI遗忘机制)。
论文中提到,这还是个需要进一步调查的早期研究方向,但这对于平衡理论上无限的上下文信息是一个很好的方法,如果真能实现,对于处理超长上下文将是个巨大突破。因此,这次发布的DeepSeek-OCR表面上是个OCR模型,但从另一个角度来看,其研究代表了一个有前景的新方向(模型前景)。这一OCR模型发布不久就在GitHub获得超过1400颗星星。
从论文署名来看,这一项目由DeepSeek三位研究员Haoran Wei、Yaofeng Sun、Yukun Li共同完成。行业消息显示,其中一作Haoran Wei曾在阶跃星辰工作过,曾主导开发了旨在实现“第二代OCR”的GOT-OCR2.0系统,因此由其主导DeepSeek的OCR项目也在情理之中。不过,DeepSeek迟迟不发R2这样的新模型,市场已经有一些声音认为其落后了,也有观点认为,DeepSeek目前只是在修炼“内功”,为下一代模型蓄力。
(文章来源:第一财经)
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。