国产大模型紧追OpenAI,算力需求持续增长
AI导读:
DeepSeek、Kimi等国产大模型团队在性能上比肩OpenAI GPT系列,定价展现极致性价比。国内外大模型厂商竞争激烈,算力需求持续增加,国产算力产业链迎来发展机遇。
在OpenAI的GPT系列模型引领AI潮流之际,国产大模型正奋力追赶,展现出强劲的发展势头。
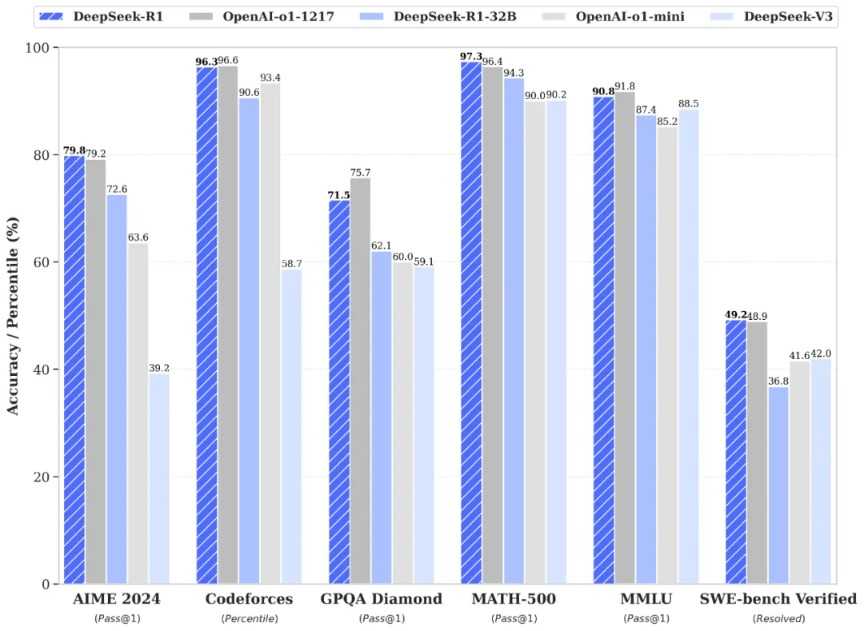
1月20日,Deepseek公司正式推出了DeepSeek-R1模型,并同步开源了模型权重。据悉,DeepSeek-R1在后训练阶段大规模运用了强化学习技术,即便在标注数据极少的情况下,也显著提升了模型的推理能力。在数学、代码编写、自然语言推理等任务上,其性能已可与OpenAI的o1正式版相媲美。根据DeepSeek公布的测试数据,DeepSeek-R1在美国AIME 2024、MATH-500和SWE-bench Verified等测试中的表现均优于OpenAI o1。其中,前两个测试专注于评估数学能力,而SWE-bench Verified则旨在衡量AI模型解决现实世界软件问题的能力。
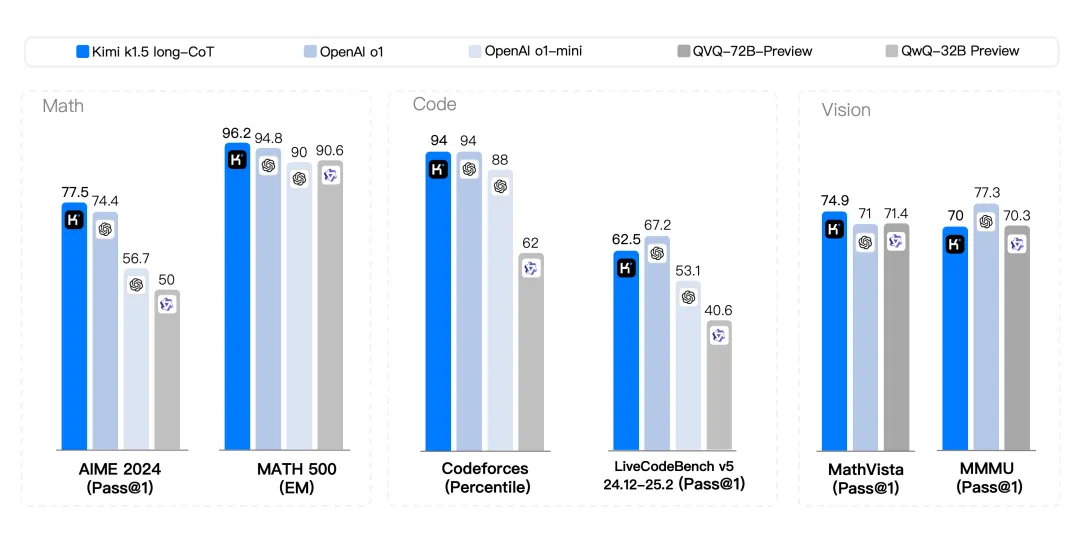
同日,Kimi公司也推出了其全新的SOTA模型——k1.5多模态思考模型。在long-CoT模式下,Kimi k1.5的数学、代码编写和多模态推理能力均达到了长思考SOTA模型OpenAI o1正式版的水平。据官方介绍,这是全球范围内OpenAI之外的公司首次实现o1正式版的多模态推理性能,Kimi技术团队还首次发布了详细的技术报告。在short-CoT模式下,Kimi k1.5的数学、代码编写、视觉多模态和通用能力更是大幅超越了全球范围内的短思考SOTA模型GPT-4o和Claude 3.5 Sonnet,领先优势高达550%。

此外,其他国产大模型同样表现出彩。1月15日,MiniMax发布了全新开源模型系列Minimax-01,在多个标准和内部基准测试中,其性能与GPT-4o、Claude3.5-Sonnet等顶尖模型不相上下,尤其在处理长上下文方面展现出卓越能力。
回顾OpenAI的发展历程,该公司在2024年5月、9月和12月分别推出了GPT-4o、GPT-o1(包括o1-preview和o1-mini,o1正式版于2024年12月发布)和GPT-o3。目前,其最强大的模型是o3,具备出色的推理能力、更丰富的科学知识储备以及更强的编码能力。而o1则以其擅长的编码、数学和写作能力,以及多模态功能支持图片上传等特点,赢得了广泛关注。
以DeepSeek为代表的国产大模型团队不仅在性能上力求比肩最先进的大模型,还在定价上展示了极致的性价比。DeepSeek-R1的API服务定价为每百万输入tokens 1元(缓存命中)/4元(缓存未命中),每百万输出tokens 16元,远低于OpenAI GPT-o1模型的定价。
随着国内外大模型厂商的激烈竞争和快速迭代,大模型对算力的需求也在持续增加。火山引擎智能算法负责人吴迪曾预测,到2027年,豆包每天的Token消耗量将超过100万亿,是当前水平的100倍以上。字节跳动旗下芜湖江东名邑科技有限公司计划在安徽芜湖建设火山引擎长三角算力中心项目,总投资高达80亿元,以满足日益增长的算力需求。此外,小米等国内厂商也在积极布局AI领域,搭建自己的GPU万卡集群,并对AI大模型进行大规模投资。
展望未来,随着字节、幻方、小米等国内厂商的积极布局,国产大模型有望快速崛起,推动国产算力需求增长,促进国产算力基础设施建设。上海证券和东莞证券等研究机构纷纷发布研报称,国产大模型的崛起以及新玩家的入局,有望拉动国内互联网大厂在算力端的支出,国内算力军备竞赛才刚刚开始,国产算力厂商将迎来前所未有的发展机遇。
在此背景下,服务器及液冷厂商、PCB厂商等有望受益;同时,数据存力和运力需求的持续攀升,也为存储、光模块和光芯片等企业创造了更多的市场机会,促使整个产业链不断优化升级,以满足日益增长的AI算力需求。
(文章来源:科创板日报)
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。





